Releasing apps at M&S
At Marks & Spencer we ship many apps (more than 100!) all the time. Two of those apps, the M&S flagship app on the App Store and Play Store, have been growing by the day, and our old, time-consuming fortnightly release process was starting to show its age.
It was time to go weekly, but getting there wasn’t going to be as easy as replacing a two with a one. We would have to take a broader look at branching, design something simple, and roll it all out to the Android and iOS codebases without disrupting the many teams in many time zones working on them. Releasing had to be less about dealing with source control, and more about ensuring quality.
This is the story of our journey towards higher quality, more frequent releases, starting with: Releasing!
Slow old Git-flow
Both our iOS and Android repos used the classic Git-flow branching structure for the longest time. If you’re not familiar with it, here’s a quick recap:
Day-to-day code lands on develop over the span of a couple of weeks, after which a release branch is cut. The release candidate is tested and stabilized on the release branch before merging a pull request to main to trigger the deployment to our customers. main would then need re-merging with develop, to ensure those fixes made on release made it in to the next one.
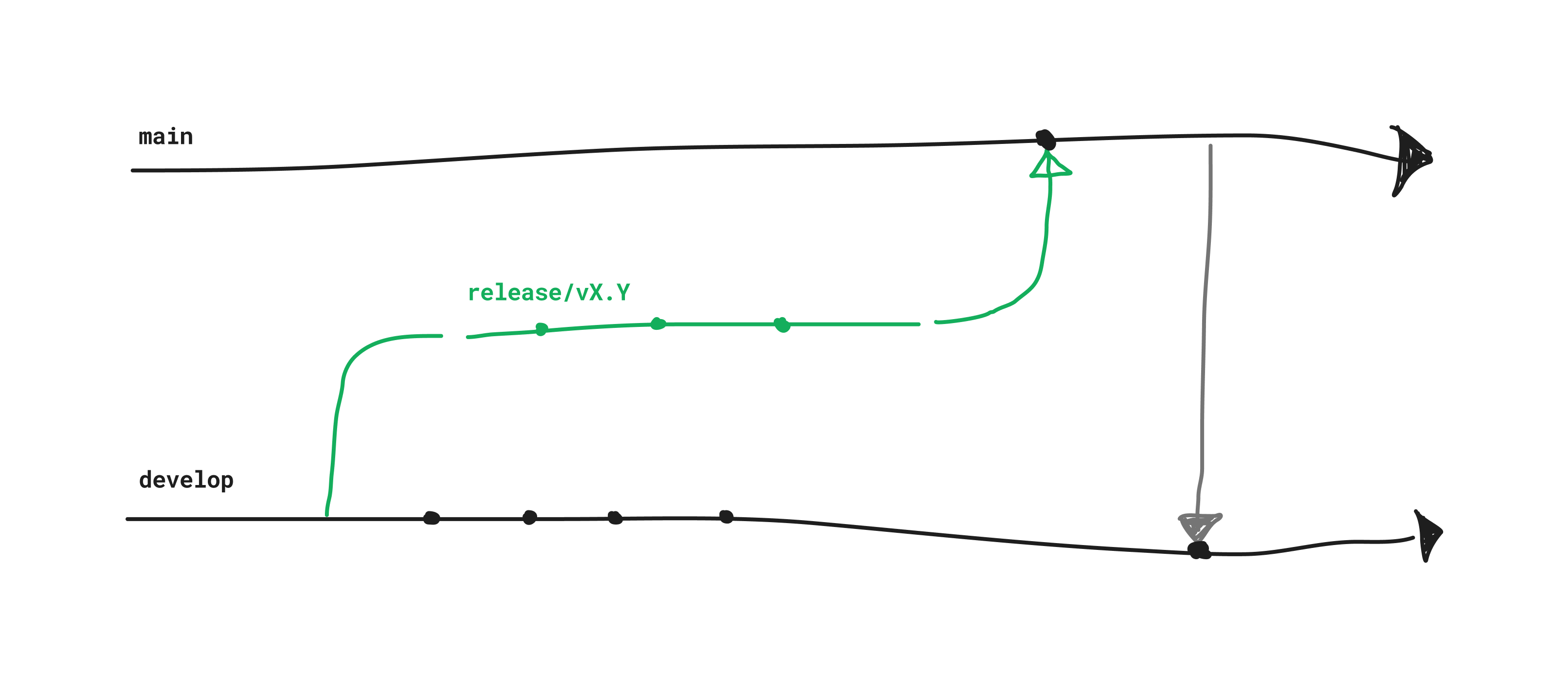 Dual-trunk branching with Git-flow
Dual-trunk branching with Git-flow
All-in-all, pretty reasonable! However, it started to become a problem for us as more and more developers started contributing. Branching from a working trunk and stabilizing was fine, as was merging to main - a target that isn’t moving. The problem was going the other way - re-integrating main with develop.
Our working trunk moved quickly, meaning that fixes made on our release branch would likely end up conflicting. Resolving this conflict ended up being a responsibility of the release champion, who sometimes wouldn’t have the context needed to action it correctly without effort. We automated as much as we could, merging this pull request automatically if there wasn’t conflicts. This meant fewer clicks of the “Accept” button, which also meant it was easier to miss that a conflict existed and not action the merge at all!
This extra cognitive load on the release champion lead to slower releases. Not only were releases harder to action, with Git-flow we miss out on fixes on the working trunk until the release is finalized. We did often mitigate this through multiple pull requests, but that’s even more cognitive load.
The one trunk to rule them all
Managing two trunks was starting to get impractical — why not get rid of one of them?
Trunk-based development is an approach where there’s one trunk branch (like main), and all work lands there. All work is releasable, made possible by feature flags and automated testing, meaning any given commit is safe to release! While this sounds great in theory, and works well in systems where rolling backwards or forwards is quick and easy, it’s problematic for mobile apps.
Apps are constrained by the stores, not shipping our releases to customers before taking their time reviewing. It takes a good amount longer for adoption to then ramp up, meaning it takes a long time to create a fix and address it. Even if we had incredible test coverage, it’s near-impossible to test every given scenario your app will be run under in production.
A branching structure growing in popularity for mobile apps nowadays is a combination of trunk-based development and release branches. Let’s explain:
Developers do their work in small, manageable chunks, and merge into a trunk branch through a workflow called GitHub Flow - branch, code, pull request, merge. Every week (or fortnight in our case), a workflow kicks off to cut a release branch from main. This release branch behaves similarly to the Git-flow release branch — it’s fixing our base at a given point, allowing us to stabilize before releasing. Fixes for the release could go one of two ways - based on release and merged into the release branch, or based on main, and back-ported to the release branch.
Merging a release branch back in to where it came from was one of the time sinks we were looking to get rid of, removing the need to resolve merge conflicts. Instead, we aimed for fixing on main, and never merging the release branch back in.
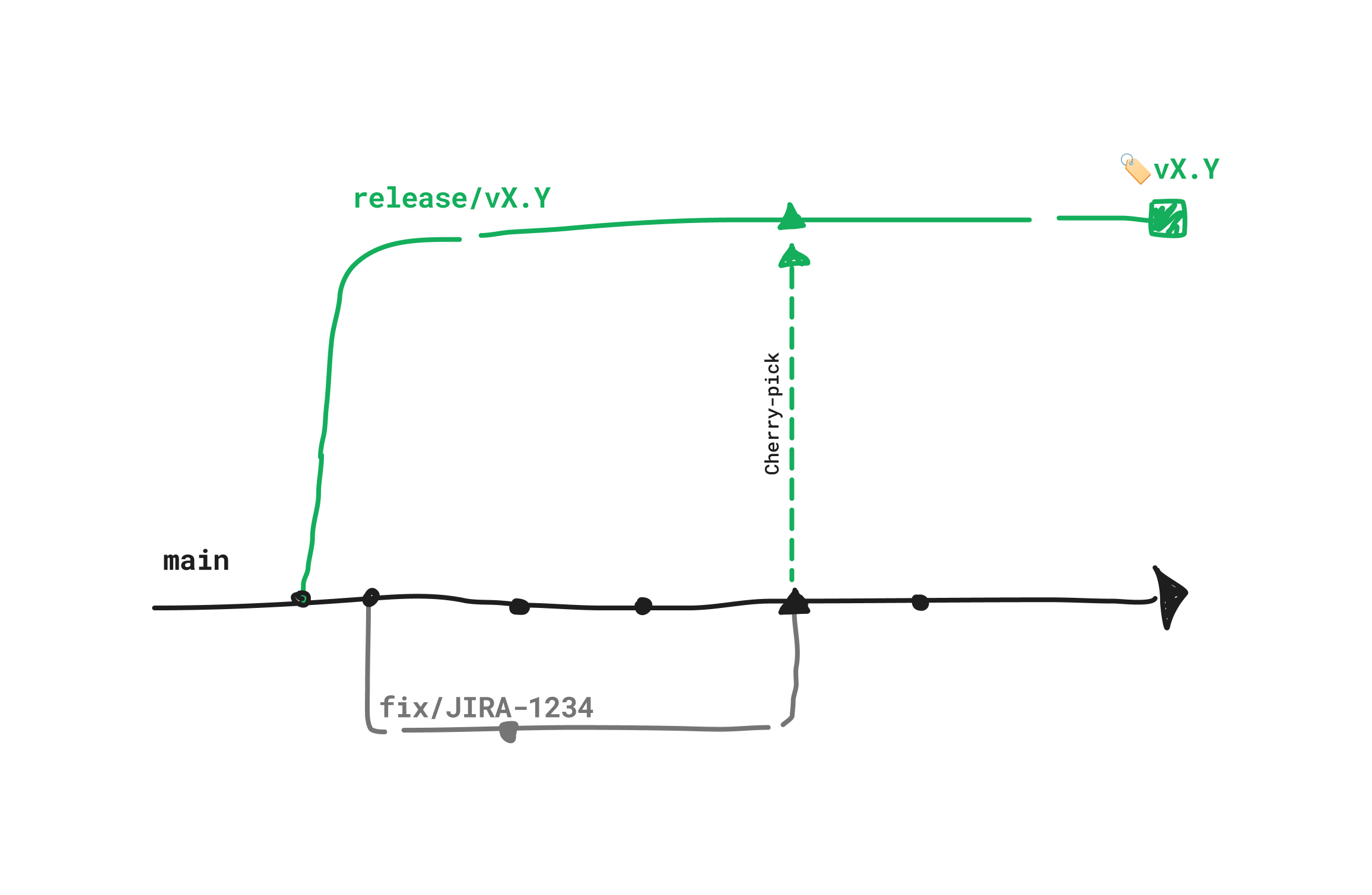 Trunk branching with release branches
Trunk branching with release branches
To make this “back-porting” simple for developers, we introduced an automatic cherry-picking workflow. When bugs come up in a release before deployment, pull requests with fixes would land in main, first. These pull requests have a special label which another piece of automation picks up on, knowing to cherry-pick the newly merged work on to the open release branch!
This works the majority of the time, but what about merge conflicts? In our old school Git-flow model, resolving conflicts ended up being the responsibility of the release champion, who may or may not have all the context needed. With our cherry-picking flow, the conflicts end up having to be resolved more with more granularity the other way around.
Developers fix their bugs on main, meaning the code they need to modify to address the issue has moved on from the base the release branch was cut from. If a fix can’t be cleanly cherry-picked onto the release branch, the author of the fix is prompted to create a pull request per-fix, addressing more granular conflicts as they come up!
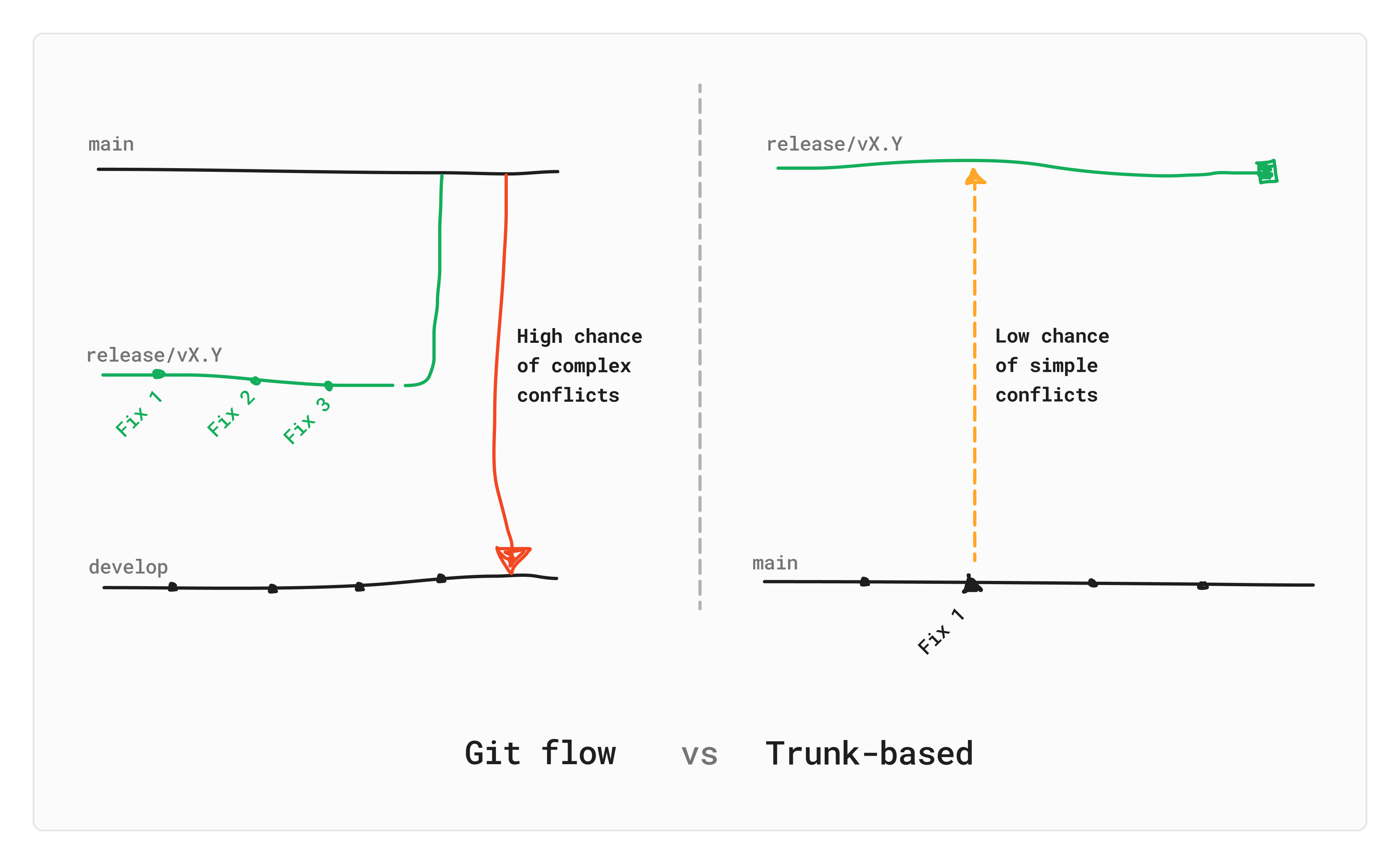 Comparing effort to resolve conflicts by branching structure
Comparing effort to resolve conflicts by branching structure
Building a release process
We use GitHub Actions at M&S, knowing from the get-go that we would be building our release process to integrate with it. We wanted a developer experience that meant engineers managing the release didn’t need to leave the repository — building our release process using GitHub Actions Workflows was the obvious choice!
There exists a surprisingly large number of ways to write GitHub Actions Workflows — here’s how we did it.
The tools
A release process is mixture of CI & CD (i.e building and deploying something), and git-ops (i.e branching, tagging, releasing). GitHub Actions is positioned as a CI/CD system out of the box, but you can do much more with it through the use of the GitHub CLI.
gh comes pre-installed on GitHub Actions runners, and offers a lot of convenient functionality for automating git operations, such as:
gh pr- list, create, and edit pull requestsgh release- create, view and edit releasesgh variable- interact with repository variables
gh commands are backed by JSON, which can be queried using jq through the --jq option. This is super powerful, allowing you to write complex data operations in a few lines of bash. Here’s how you might use JQ to fetch all the URLs for open pull requests with the “Release” label:
existing_release_pr_urls=$(
gh pr list \
--state open \
--label Release \
--json url \
--jq '.[].url'
)
It’s trivial to use gh for write operations, as long as you use a token with the right permissions. We use Repository Variables to store the latest version code of a release while it’s stabilizing. Getting and setting this variable is a one-liner:
gh variable set "${VERSION_VAR}" --body "${VERSION_CODE}"
To use gh you need to provide it with a token through an environment variable. The automatically-authenticated GITHUB_TOKEN secret gets you most of the way there, but in some cases we found that GitHub Actions’ permission model doesn’t line up with the permission model of the GitHub API. It’s easy enough to create your own PAT and store it in your Actions Secrets, which we did to make use of gh when querying org-level information.
Working on complex Workflows
We set out on implementing everything we need for a release process using what GitHub Actions gives you out-of-the-box — workflow composition through workflow_call triggers, job dependencies to create release “pipelines”, and bash steps to work the gh magic.
Designing the solution was the easy part — implementing it with confidence that it wouldn’t break immediately was much harder.
GitHub Actions workflows are similar to other declarative workflow formats you’ll see supported by other providers — they’re Yaml files with a custom schema. While this makes for easy reading, it means there’s no easy way to unit test them. We have a system in-place to test reusable workflows, built on top of Act, but we knew that testing workflows this complex would be incredibly time-consuming — we needed to be more nimble.
Instead, we created a sandbox repository. This repository was carefully crafted to mirror the exact branching structure and branch protection models of the main Android repository, giving us a prod-like environment to test our workflows against. To make sure we could iterate quickly, we stubbed workflows which were expected to build and test the project, allowing us to focus on our release workflows in isolation.
By using a sandbox for testing, we could try many different approaches, breaking things as needed, and make as many releases as we could to test the process end-to-end and build our confidence. In the end, we had created more than 100 releases, covering all the scenarios we had accounted for. With the workflows looking and feeling as good as we could make them, it was time to roll out.
Rolling out
Rolling out major branching changes alongside a revamp of a release process is not an easy task. We would have to block access to writing to our trunk branch(es) for a time during the cut-over, which would stop developers from merging their code. We needed to ensure this downtime was during quiet hours, so we set a target of a Friday morning at 7am BST and got planning.
Our plan took the shape of a run book - a series of checkboxes which would take us from our two-trunk world, to trunk-based with release branches. These checkboxes were nuanced, and some more complex than others. We did as much work ahead-of-time as possible — creating pull requests, scripts of run to modify things in batches, and preparation of branch protection rules in parallel. When this run book eventually looked comprehensive, we trial-ran it in our sandbox, exposing a few blind-spots.
When it came time to execute, we joined a call and paired on the run book - one person actioning the bullet points, the other taking notes. It took about half an hour to work through, done and ready to use an hour before engineers would start coming online!
Aiming for portability
Across M&S we have more than 100 mobile applications in their own individual repositories. Each of these has a distinct release process, automated to varying degrees, with different branching structures throughout. This produces significant cognitive load when working across multiple projects, leading to slower iteration cycles, and ultimately leaving value on the table for our Colleagues and Customers.
In solving the release process for the highest traffic repositories, we saw an opportunity to take our newly found insight and apply it to all of our other applications. Built from the ground with conventions and portability in mind, our new process can solve branching and releasing across many code bases and teams, with the flexibility to scale up and service large, highly collaborative repositories. Here’s how we did it:
Our release process can be summarized as just two manual steps:
- Create the release branch (
release/X), and wait for stability. - Deploy the release to production, and perform any associated admin.
Along the way, we have automated processes that kick in and do the rest of the work: Commits to release branches submit builds to the stores, and a special cherry-pick label manages fixes destined for the release.
The common points across all mobile release then end up being:
- A release branches (
release/X) is cut from themainbranch. - Commits to
release/Xbuilds the apps, and stages them somewhere. - Releases are “finalized”, promoting the latest build and sending any relevant communications.
“Finalizing” a release tends to involve a lot of repository-specific steps that need to be completed to call a release “done”. The common parts here are our git operations - creating and tagging a release, closing off the release branch & pull request, and deleting any state we might have had hanging around, like labels. For everything else, we follow a Producer and Consumer model. By making heavy use of reusable workflows, we can share the common parts, like building release variants of apps and storing them in artifacts. Repositories can then implement their own Consumers of these produced artifacts, like deploying a pre-built application to Huawei App Gallery, or doing custom reporting on test results.
Our approach to portability is already starting to pay off. We’ve recently reused the same code in iOS, leveraging reusable workflows to share portions of our process, and are generalizing more and more of the process to apply to all our other applications!
Conclusion
Our first step towards weekly releases was to get the process right. Dual-trunks were a bottleneck at our scale, and things needed to change. Moving to a single trunk with familiar release branching simplified the day-to-day of our developers, and made championing a release a breeze.
By focussing on minimizing the strain on developers writing, merging and shipping code, we open the door to more focus on quality. We shifted merge conflict responsibility further left, simplifying the role of the engineering managing the release. Our release processes are now significantly easier to work with, taking just single-digit minutes of manual intervention per-release. This all contributes to freeing up developer time for more important things, like testing and polish.
Nailing the process isn’t everything, and there’s more to do to keep our quality high before we get to weekly releases, but it’s a big step in the right direction.